Monitoreo y respuesta
en tiempo real.
Un agente que vigila tu infraestructura 24/7, detecta anomalías y responde a incidentes antes de que tu equipo se entere.
$monitor--all --alertas críticas
✓ API Gateway · 12ms · OK
✓ DB Cluster · 4ms · OK
⚠ Workers-EU · latencia 380ms · umbral 200ms
Analizando causa raíz…
✓ Redireccionando tráfico a Workers-US
Notificando a on-call: [email protected]
✓ Incidente resuelto · downtime: 0s
█Los incidentes no avisan cuándo van a ocurrir. Tu NOC humano, sí.
Tiempos de respuesta lentos se traducen en downtime, pérdidas y clientes enojados. Y depender de quién esté de guardia es un riesgo que no deberías correr.
- Detección lenta
Los incidentes se detectan tarde, cuando el downtime ya afecta a los clientes.
- Downtime costoso
Cada minuto de caída representa pérdidas directas y clientes enojados.
- Sin monitoreo
Depender de quién esté de guardia es un riesgo innecesario para tu infraestructura.
- Respuesta manual
Los tiempos de respuesta humana son lentos comparados con la velocidad del incidente.
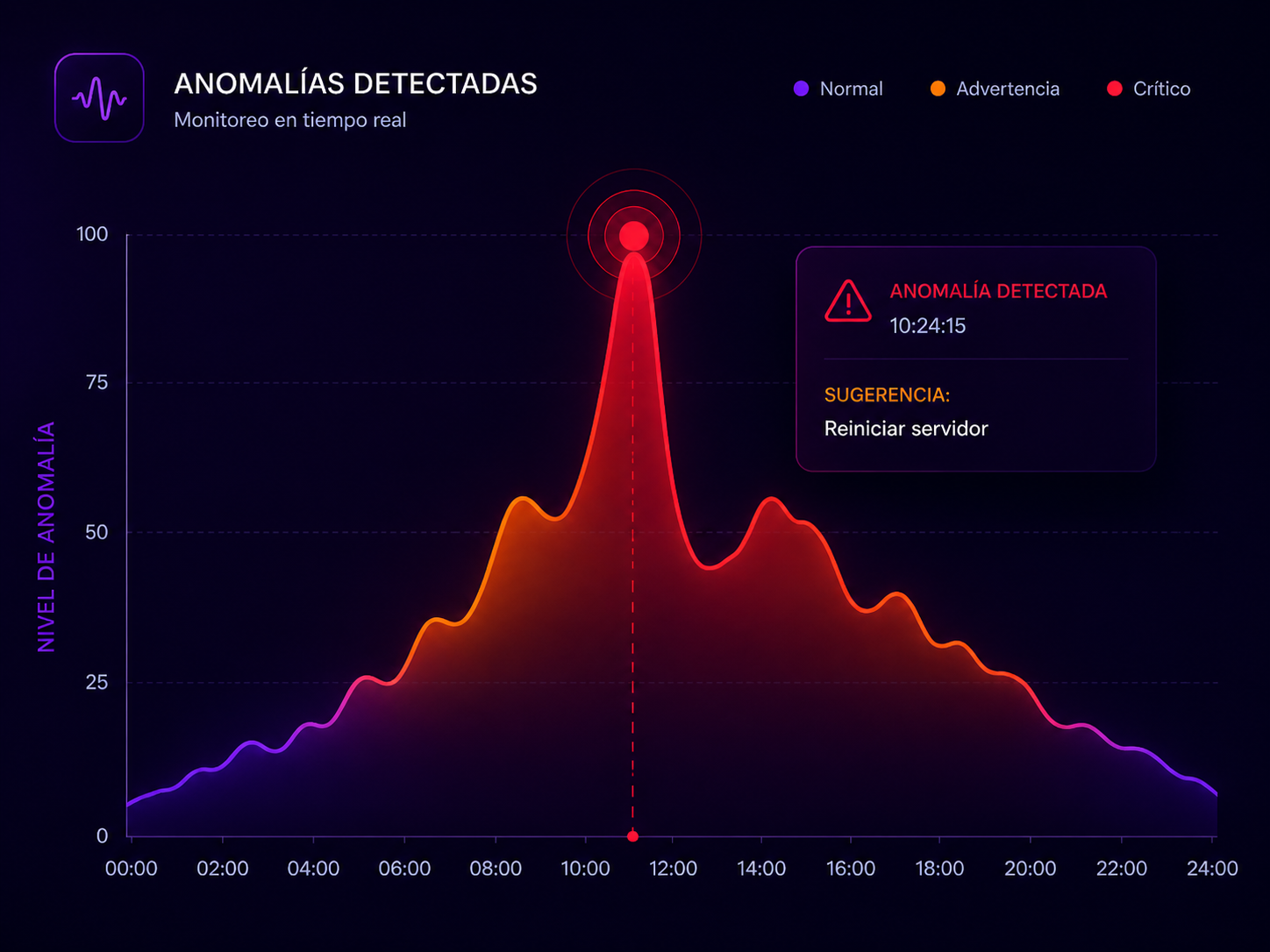
Visibilidad completa de tu infraestructura.
El agente monitorea métricas clave y genera alertas antes de que los umbrales críticos se alcancen.
Detecta, responde y notifica. Sin intervención humana.
Monitoreo continuo
El agente vigila métricas de CPU, memoria, latencia y errores en todos tus servicios configurados.
Detección y diagnóstico
Cuando una métrica supera el umbral, el agente diagnostica la causa raíz en segundos.
Respuesta o escalado
Ejecuta el playbook automático si puede. Si no, escala al on-call correcto con contexto completo.
Tu infraestructura, vigilada 24/7.
Agenda una demo y te mostramos el agente respondiendo a un incidente real en tiempo real.
Hola ¿En qué puedo ayudarte?